The Sharpe Ratio
Assuming returns are normally distributed.
Well, traditionally, we do $SR= \frac{E[R] - r}{\sigma}$. But close enough. The truth is, the Sharpe Ratio is more of a means of comparing strategies of similar capacity rather than being a standalone metric. Actually, without the contex of the trading frequency and the capacity, a Sharpe Ratio by itself is pretty uninformative. A Sharpe Ratio of 2 for ultra-high-frequency strategy is quite unimpressive, while it is extremely rare for a fundamental, long-term investor to maintain this performance for a significant amount of time.
It turns out that the limiting distribution of the Sharpe Ratio is Gaussian. Actually, this is the case even if returns are non-Normal. You can thank the CLT and the asymptotic distribution of the MLE for that.
\[\begin{equation*} \text{we have } \sqrt{n} (\hat{SR} - SR) \Longrightarrow N(0, 1+ \frac{SR^2}{2}) \end{equation*}\]Derivation of the Variance of the Sharpe Ratio
Assume Returns $R_t \overset{\text{iid}}{\sim} N(\mu, \sigma^2)$
Our parameters vector is $\theta = (\mu, \sigma^2)^T$
From the Asymptotic normality of the MLE, we have \(\sqrt{m} (\hat{\theta} - \theta) \xrightarrow{d} N(0, V)\) with \(\begin{equation*} V = \begin{pmatrix} \sigma^2 & 0 \\ 0 & 2\sigma^4 \end{pmatrix} = I^{-1} \end{equation*}\)
Here, $I$ is the Fisher Information matrix, defined as \(I = - E \left[ \frac{\partial^2 \ell(\theta)}{\partial \theta^2} \right]\)
Then the MLE is: \(\hat{\theta} = \begin{pmatrix} \frac{1}{n} \sum R_i \\ \frac{1}{n} \sum (R_i - \bar{R})^2 \end{pmatrix}\)
The Delta Method gives: \(\sqrt{n} (g(\hat{\theta}) - g(\theta)) \xrightarrow{d} N(0, \frac{\partial g(\theta)}{\partial \theta}^T V \frac{\partial g(\theta)}{\partial \theta})\) where $\frac{\partial g(\theta)}{\partial \theta}$ is the Jacobian matrix = \(\begin{pmatrix} \frac{1}{\sigma} \\ -\frac{\mu}{2\sigma^3} \end{pmatrix}\)
Hence we have \(\frac{\partial g(\theta)^T}{\partial \theta} V \frac{\partial g(\theta)}{\partial \theta} = \begin{pmatrix} \frac{1}{\sigma} & -\frac{\mu}{2\sigma^3} \end{pmatrix} \begin{pmatrix} \sigma^2 & 0 \\ 0 & 2\sigma^4 \end{pmatrix} \begin{pmatrix} \frac{1}{\sigma} \\ -\frac{\mu}{2\sigma^3} \end{pmatrix} = \begin{pmatrix} \sigma & -\mu\sigma \end{pmatrix}\begin{pmatrix} \frac{1}{\sigma} \\ -\frac{\mu}{2\sigma^3} \end{pmatrix} = 1+ \frac{\mu^2\sigma}{2\sigma^3} = 1 + \frac{1}{2} SR^2\)
Relationship to $t$-stat
You want to test whether the returns of your strategy are statistically significant (different from 0 really). If you regress $R_t \sim 1$ (i.e. predicting the returns using only an intercept), you can test whether the hypothesis test $\beta_0 = 0$ (the intercept) using the t-statistic from OLS. Recall \(t = \frac{\hat{\beta}}{SE(\hat{\beta})}\) We have:
- $\hat{\beta} = \mathbb{E}[R_t]$
- $SE(\hat{\beta}) = \sigma \sqrt{(X^TX)^{-1}}$, with
- $\sigma = \frac{1}{\sqrt{n-1}} \sqrt{\Sigma(R_t - \beta_0)^2} = \frac{1}{\sqrt{n-1}}\sqrt{\Sigma(R_t - \mathbb{E}[R_t])^2} = \sigma_R$
- $\sqrt{(X^TX)^{-1}} = \sqrt{\Sigma 1} = \sqrt{n}$
So we get
\[t = \frac{\hat{\beta}}{SE(\hat{\beta})} = \frac{\mathbb{E}[R_t]}{\sqrt{n} \cdot \sigma_R} = \frac{1}{\sqrt{n}} \cdot SR\]So we can see that the Sharpe Ratio is equivalent to the t-statistic for $\beta_0$ up to a scaling constant.
Time Aggregation
When we talk about Sharpe Ratio we generally talk about the Annualized Sharpe Ratio, which would be the SR measured on yearly returns. But we can transform the SR measured w.r.t shorter time periods t into a SR measured w.r.t longer time periods T (assuming t divides T), let $q = T/t$.
We know that \(R_T = \sum^q_i R_t^{(i)}\)
Under the assumption of i.i.d returns $R_t$,
\[\mathbb{E}[R_T] = q \cdot \mathbb{E}[R_t] \qquad \text{ and } \qquad Var[R_T] = q\cdot Var[R_t]\] \[SR[R_T] = \frac{q \cdot \mathbb{E}[R_t]}{\sqrt{q\cdot Var[R_t]}} = \sqrt{q}\cdot SR[R_t]\]Sharpe Ratio under non-normality
We have shown that under normality conditions $Var(SR) = 1+ \frac{SR^2}{2}$. If we drop the normality conditions fo the returns, we can show that:
\[Var(SR) = 1+ \frac{SR^2}{2} - SR \cdot \gamma_3 + SR^2 \cdot \frac{\kappa - 3}{4}\]where $\gamma_3$ is the skew of returns and $\kappa$ the kurtosis. There are several consequences of using the standard variance formula instead of the true one under non-normality of returns:
- $\gamma_3 > 0$ makes the standard variance $Var(SR) = 1+ \frac{SR^2}{2}$ inflated where as the true variance would be lower. This makes the SR look less significant. Opposedly, a negative skew $\gamma_3 < 0$ will make the standard SR look more significant.
- Similarly, high kurtosis $\kappa>3$ makes the standard variance formula lower than it really is. This makes the SR look better.
Combining Portfolios
I will do something that is generally well-appreciated in the mathematical literature and change notations. So far we denoted the Sharpe Ratio as $SR$. Now I’m changing to $S$. And $P$ denotes a portfolio. It looks like that:
\[\begin{equation*} P = \sum w_i X_i \end{equation*}\]Let $C$ be the covariance matrix of $X$ : $C_{ij} = \text{cov}(x_i, x_j)$
\[\begin{align*} E[P] &= \sum w_i E[P_i] \\ \text{Var}(P) &= \sum\sum w_i w_j \text{cov}(X_i, X_j) = w^T C w \end{align*}\]Independent strategies:
Let $S_i = \frac{E[X_i]}{\sigma_i}$
Assume strategies are $iid$, so $S_i = S_j = S$.
\[\begin{align*} \text{Var}(P) = \sigma_P^2 &= \frac{1}{n^2} \sum \sigma^2 = \frac{\sigma^2}{n}\\ \sigma_P &= \frac{\sigma}{\sqrt{n}}\\ E(P) &= \frac{1}{n} \sum E[X_i] = \frac{1}{n} \sum S_i \sigma_i\\ \\ S_P &=\frac{E(P)}{\sigma_P} = \frac{\frac{1}{n}\sum S_i \sigma_i}{\frac{\sigma}{\sqrt{n}}} = \frac{S\sigma}{\frac{\sigma}{\sqrt{n}}} = \sqrt{n} S \end{align*}\]So you can see that the Sharpe Ratio scales at best with the square root of number of strategies.
Correlated strategies:
Here we assume that the strategies all share the same correlation $\text{Corr}(X_i, X_j) = \rho$. We still have \(E[P] = \frac{1}{n} \sum S_i \sigma_i\).
\[\begin{align*} \sigma_P^2 &= \text{Var}(\frac{1}{n} \sum X_i) = \frac{1}{n^2} \sum \text{Var}(X_i) + \frac{1}{n^2} \sum_{i \neq j} \text{Cov}(X_i, X_j) \\ &= \frac{1}{n^2} [n \sigma^2 + n(n-1) \rho \sigma^2] = \frac{\sigma^2}{n} [1+(n-1)\rho] = \frac{\sigma^2}{n} [1+(n-1)\rho] \end{align*}\]So
\[S_P = \frac{E(P)}{\sigma_P} = \frac{\frac{1}{n} \sum S_i \sigma_i}{\frac{\sigma}{\sqrt{n}} \sqrt{1+(n-1)\rho}} = \frac{\sqrt{n}}{\sqrt{1+(n-1)\rho}}S\]Number of effective strategies in the correlated case:
If we had $N_{eff}$ independent strategies: $\sigma_P^{eff} = \frac{\sigma}{\sqrt{N_{eff}}}$
So, \(\frac{\sigma}{\sqrt{N_{eff}}} = \frac{\sigma}{\sqrt{n}} \sqrt{1+(n-1)\rho}\) \(\Rightarrow N_{eff} = \frac{n}{1+(n-1)\rho}\)
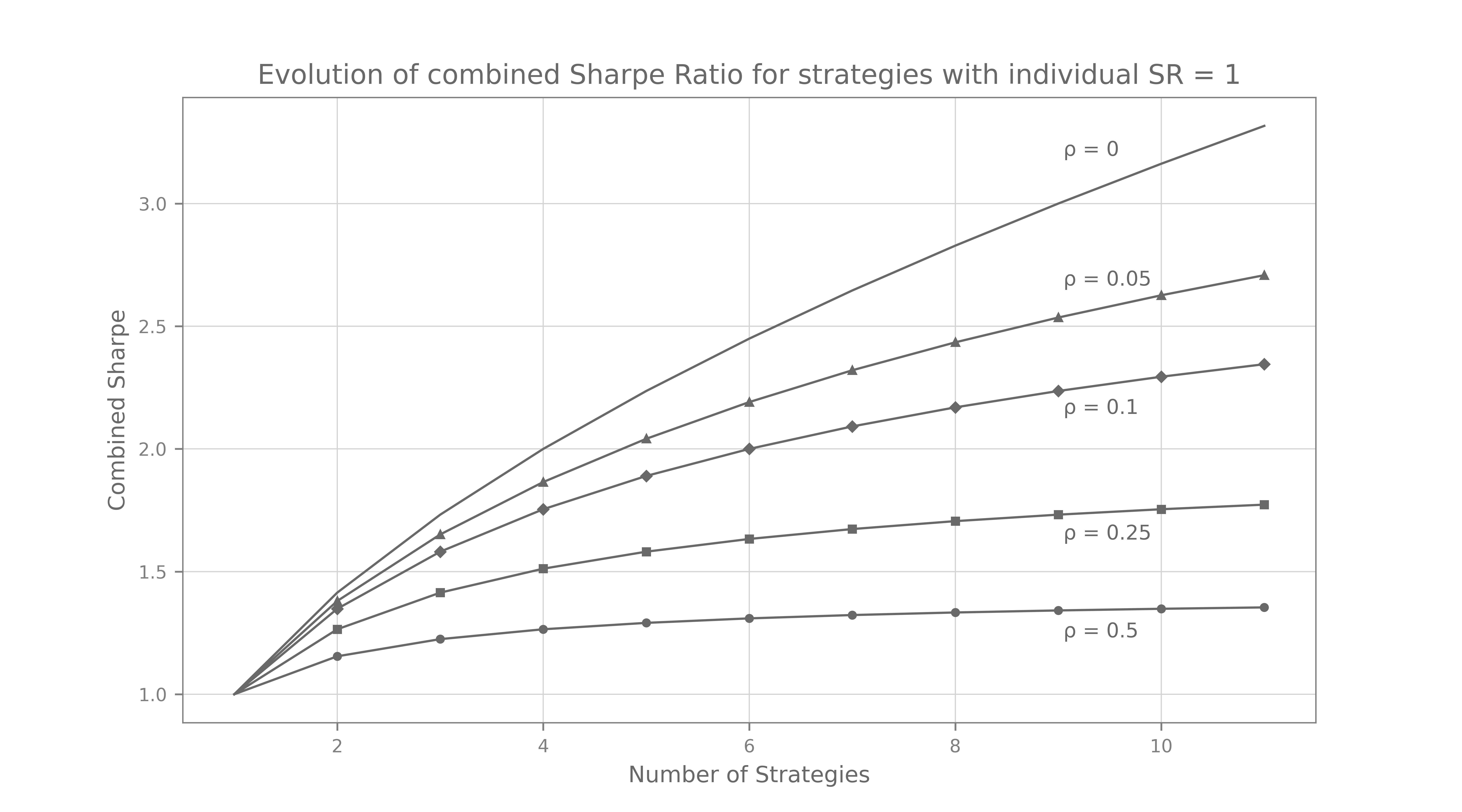
The plot above shows the evolution of the combined Sharpe of x strategies all with individual Sharpe Ratio of 1. One can easily see how correlation within strategies hinder the global performance of the combined portfolio. Scalability of a hedge fund depends mostly on how uncorrelated the individual strategies are. This is why Millenium pods cannot talk to each other, by the way — to make sure that alpha doesn’t leak from one portfolio to another.
Drawdowns (advanced)
If you’re wondering how I derived that, I didn’t. I stole it. From Gappy. This is slightly advanced, and I have not used it in practice. But upon reading it, I thought I needed to make a note, so here it is. I certainly hope that my next interviewer for a QR position will not find this blog and ask about it, otherwise I’m cooked. Not even sure that this has its place on this blog. This is not even Sharpe Ratio anymore.
Consider the PnL of a strategy as a diffusion $X_t$ with drift $\mu > 0$ and volatility $\sigma$. We can interpret $\mu$ as the expected daily PnL and $\sigma$ as the daily vol. \(dX_t = \mu dt + \sigma dB_t\) \(X_0 = 0\)
Define the Sharpe $SR_T = \frac{\sqrt{T} \mu}{\sigma}$ and $\sigma_T = \sigma \sqrt{T}$ for a given horizon $T$. When considering a drawdown $-b$, we also define the normalized drawdown $b_{\sigma} = b/\sigma$
- DD probability: $P(b) = P(X_t \leq b \text{ for some } t>0)$ \(P(b) = \exp \Bigl\{ - \frac{2 \mu b}{\sigma^2}\Bigl\} = \exp ( -2 b_\sigma SR)\)
-
Stationary distribution of DD $D_t = max_{0\leq s\leq t} X_s - X_t$ \(P(D_t>=b) \rightarrow^{t \rightarrow \infty} \exp \Bigl\{ - \frac{2 \mu b}{\sigma^2}\Bigl\} = \exp ( -2 b_\sigma SR)\)
It follows that the average drawdown is \(E(D_t) = \frac{\sigma^2}{2 \mu} \Leftrightarrow \frac{E(D_t)}{\sigma} = \frac{1}{2SR}\)
-
Expected recovery time. Let \(D(t^{*}) = -b <0\) meaning that at time \(t^*\), the process \(X_{t^*}\) is \(b\) below its prior maximum. Define
\[\tau(b) = \inf \{ t \geq 0: D_{t^* + t} = 0 | D_{t^*} = -b\}\]The expected time to recover is:
\[E(\tau) = \frac{b}{\mu} = \frac{b_{\sigma}}{SR}\]One can also show
\[\text{std}(\tau) = \frac{b \sigma^2}{ \mu^3} = \sqrt{\frac{b_\sigma}{SR}}\frac{1}{SR}\]To estimate the expected time spent in a DD, we can integrate the expected time to exit $-b$ w.r.t its stationary distribution defined above
\[\begin{align*} \qquad \qquad \qquad \qquad \qquad \int_0^{\infty} \frac{2\mu}{\sigma^2} \frac{b}{\mu} \exp \Bigl\{ - \frac{2 \mu b}{\sigma^2}\Bigl\} db &= \frac{2}{\sigma^2} \int b \exp \{-kb\} \qquad \text{with}\quad k=2\mu /\sigma^2\\ &= \frac{2}{\sigma^2}\frac{1}{k^2}\\ &= \frac{1}{2SR^2} \end{align*}\]
References
Sharpe Ratio: Estimation, Confidence Intervals, and Hypothesis Testing (2018)
Matteo Riondato; Labs, Two Sigma Investments, LP
Paper
Comments on the Variance of the IID estimator in Lo (2002) (2002)
Elmar Mertens
Paper
Reading, Writing and Drawdown Arithmetic (2025)
Giuseppe Paleologo
Article