Regularization in Regression
The Problem
Shrinkage methods are used for two reasons: to deal with multicollinearity and do variable selection. When high multicollinearity is present, the design matrix $X^TX$ becomes degenerate. When perfect multicollinearity is present, $rank(X^TX) < n$ and the matrix is singular and thus non-invertible, so it is impossible to solve OLS. As a motivating example, perform the eigendecomposition of the design matrix:
\[X^TX = Q\Lambda Q^{-1}\]Here $Q$ is a $n\times n$ matrix whose $i$th column is the $i$th eigenvector of $X^TX$. $\Lambda$ is a diagonal matrix of the eigenvalues of $X^TX$. In the case of non-perfect multicollinearity, i.e. when no eigenvalues are 0, then $X^TX$ is invertible and its inverse is given by:
\[(X^TX)^{-1} = Q\Lambda^{-1} Q^{-1}\]where $\Lambda^{-1}$ is the diagonal matrix with inverse eigenvalues, e.g. $1/\lambda_i$. One can easily see that if $X^TX$ is close to singular then some if its eigenvalues will be close to 0, making exploding $\beta$.
Ridge
General Form
Instead of minimizing $|y-X\beta|^2$ (MSE) we now minimize $|y-X\beta|^2 + \lambda |\beta|^2$. This can also be formulated as
\[\textit{minimize} \quad RSS \quad \text{subject to} \quad \Sigma\beta^2<t\] \[\hat{\beta}{_{RIDGE} = (X^TX + \lambda I)^{-1}X^Ty}\]The term $\lambda |\beta|^2$ is called the shrinkage penalty. When it is 0 we fall back to OLS. The $\hat{\beta}$ in OLS are scale invariant, multiplying $X_i$ by $c$ gives a new $\hat{\beta}_i$ scaled by $1/c$. So we must normalize the predictors before applying any shrinkage method. Ridge regression’s advantage over least squares is rooted in the bias-variance trade-off. As $\lambda$ increases, the flexibility of the ridge regression fit decreases, leading to decreased variance but increased bias. We can see that in the case where $X^TX$ is singular, the additional diagonal term $\lambda I$ will push eigenvalues slightly upward, forcing it ot be non-singular. This is especially useful when $p > n$.
As SVD
Setting $X = UDV^T$ with $U$ and $D$ being unitary matrix (orthogonal if $X$ is real).\ The columns of $V$ are the right-singular vectors and eigenvectors of $X^TX$ and the columns of $U$ are the left-singular vectors and eigenvectors of $XX^T$. The non-zero elements of D are the singular values, i.e. the square roots of the eigenvalues of $X^TX$ (or $XX^T$). But you already knew that, right? Right?
\[\begin{align*} \hat{\beta} &= (X^T X)^{-1} X^T Y\\ &= (V D U^T U D V^T)^{-1} V D U^T Y\\ &= (V D^2 V^T)^{-1} V D U^T Y\\ &= V D^{-2} V^T V D U^T Y\\ &= V D^{-1} U^T Y \end{align*}\] \[\begin{align*} \hat{\beta}_{RIDGE} &= (X^T X + \lambda I_p)^{-1} X^T Y\\ % &= (V D U^T U D V^T + \lambda I_p)^{-1} V D U^T \\ &= (V D^2 V^T + \lambda I_p)^{-1} V D U^T Y\\ &= (V (D^2 + \lambda V^T V))^{-1} V D U^T Y\\ &= V (D^2 + \lambda I_n)^{-1} V^T V D U^T Y\\ &= V (D^2 + \lambda I_n)^{-1} D U^T Y\\ \end{align*}\]The ridge estimates are essentially the OLS estimates $\hat{\beta}=V D^{-1} U^T Y=V (D^2)^{-1}D U^T Y$ multiplied by the term $\frac{D^2}{D^2 + \lambda I_n}$, which is always between 0 and 1. This has the effect of shifting the coefficient estimates downward. The coefficients with a smaller corresponding value $d_i$ (the $i$th diagonal of $D$) will be whrunk more than coefficients with a large $d_i$. So covariates that account for very little of the variance in the data will be shifted to zero more quickly.
Lasso
General Form
Lasso differs from Ridge by minimizing the L1 norm of the $\beta$ coefficients instead of L2: we know minimize $|y-X\beta|^2 + \lambda |\beta|$. The Lasso does not have a closed-form solution as you cannot directly differentiate this expression w.r.t $\beta$ due to the absolute value norm. This can also be formulated as
\[\textit{minimize} \quad RSS \quad \text{subject to} \quad \Sigma|\beta|<t\]Lasso has the property that it can set coefficients $\beta_j$ directly to 0. This can be interpreted through the subgradient conditions:
\[\begin{align*} L(\beta) &= \frac{1}{2}\|y-X\beta\|^2 + \lambda |\beta|\\ \partial L(\beta) &= X^T(X\beta - y) + \lambda\partial |\beta| \quad \text{(full gradient on first term)} \end{align*}\]The optimality condition says that $\hat{\beta}$ minimizes $L$ iff $0 \in \partial L(\hat{\beta})$. For coefficient $j$, this becomes: \(0 = X_j^T(X\hat{\beta} - y) + \lambda s_j \quad \text{where } s_j \in \partial \|\hat{\beta}_j\|\)
Case 1: If $\hat{\beta_j}= 0$
Then $s_j \in [-1, 1]$, so we need:
\[\begin{align*} 0 &= X_j^T(X\hat{\beta} - y) + \lambda s_j \\ s_j &= -\frac{1}{\lambda}X_j^T(X\hat{\beta} - y) \end{align*}\]This is valid only if \(\|s_j\| \leq 1\), which means:
\[\begin{equation*} \left|X_j^T(X\hat{\beta} - y)\right| \leq \lambda \end{equation*}\]Therefore, $\hat{\beta}_j = 0$ is optimal if and only if the correlation between the residual and feature $j$ is less than $\lambda$.
Case 2: If $\hat{\beta_j} \neq 0$
Then $s_j = \text{sign}(\hat{\beta}_j)$, so:
\[\begin{equation*} X_j^T(X\hat{\beta} - y) = -\lambda \cdot \text{sign}(\hat{\beta}_j) \end{equation*}\]The subgradient is constant ($\pm\lambda$) regardless of the magnitude of $\beta_j$. This creates a constant push toward zero of size $\lambda$, which drives coefficients smaller than $\lambda$ to 0. Ridge regression ($\lambda|\beta|^2$), whose gradient $2\lambda\beta_j$ is proportional to the current value—large coefficients get large shrinkage, small ones get small shrinkage, asymptotically approaching but never reaching zero.
Bayesian Interpretation
We can explain Ridge and Lasso through a Bayesian interpretation”
\(\mathbb{P}(\beta|X,Y) \propto \mathcal{L}(Y|X, \beta) \cdot \mathbb{P}(\beta)\)
with $\mathbb{P}(\beta|X,Y)$ being the posterior distribution of $\beta$ given the data, $\mathcal{L}(Y|X, \beta)$ the likelihood and $\mathbb{P}(\beta)$ our prior on the distribution of $\beta$.
Given $Y|X, \beta \sim N(X\beta,\sigma^2I)$
\(\mathcal{L}(Y|X, \beta) = \Pi \frac{1}{\sqrt{2\pi\sigma^2}} \exp{\biggl\{ -\frac{(y-X\beta)^2}{2\sigma^2}\biggl\}} = \Big( \frac{1}{\sqrt{2\pi\sigma^2}}\Big)^n \exp{\biggl\{-\frac{1}{2\sigma^2}\Sigma \varepsilon_i^2\biggl\}}\)
Ridge
Assumes Gaussian prior: $\beta \sim N(0, \tau^2)$ \(\begin{align*} \hat{\beta}_{RIDGE} = argmax \hspace{.4em} \mathbb{P}(\beta|X,Y) &= argmax \hspace{.4em} \Bigg\{ \Big( \frac{1}{\sqrt{2\pi\sigma^2}}\Big)^n \exp{\biggl\{-\frac{1}{2\sigma^2}\Sigma \varepsilon_i^2\biggl\}} \cdot \Big( \frac{1}{\sqrt{2\pi\tau^2}}\Big)^p \exp{\biggl\{-\frac{1}{2\tau^2}\Sigma \beta_i^2\biggl\}} \Bigg\}\\ &= argmax \hspace{.4em} \Bigg\{ \exp{\biggl\{-\frac{1}{2\sigma^2}\Sigma \varepsilon_i^2 -\frac{1}{2\tau^2}\Sigma \beta_i^2\biggl\}} \Bigg\}\\ &= argmin \hspace{.4em} \bigg\{ \frac{1}{2\sigma^2}\Sigma \varepsilon_i^2 +\frac{1}{2\tau^2}\Sigma \beta_i^2\biggl\} \bigg\}\\ &= argmin \hspace{.4em} \bigg\{ RSS +\frac{\sigma^2}{\tau^2}\Sigma \beta_i^2\biggl\} \qquad \qquad \text{which is RIDGE with $\lambda = \frac{\sigma^2}{\tau^2}$} \\ \end{align*}\)
Lasso
Assumes Laplace / Double exponential prior: \(\beta \sim \frac{1}{\sqrt{2b}} \exp{\big\{ - \frac{\Sigma |\beta|}{b}\big\}}\) \(\begin{align*} \hat{\beta}_{RIDGE} = argmax \hspace{.4em} \mathbb{P}(\beta|X,Y) &= argmax \hspace{.4em} \Bigg\{ \Big( \frac{1}{\sqrt{2\pi\sigma^2}}\Big)^n \exp{\biggl\{-\frac{1}{2\sigma^2}\Sigma \varepsilon_i^2\biggl\}} \cdot \Big( \frac{1}{\sqrt{2b}}\Big)^p \exp{\biggl\{-\frac{1}{b}\Sigma |\beta_i|\biggl\}} \Bigg\}\\ &= argmax \hspace{.4em} \Bigg\{ \exp{\biggl\{-\frac{1}{2\sigma^2}\Sigma \varepsilon_i^2 -\frac{1}{b}\Sigma |\beta_i|\biggl\}} \Bigg\}\\ &= argmin \hspace{.4em} \bigg\{ \frac{1}{2\sigma^2}\Sigma \varepsilon_i^2 +\frac{1}{b}\Sigma |\beta_i|\biggl\} \bigg\}\\ &= argmin \hspace{.4em} \bigg\{ RSS +\frac{2\sigma^2}{b}\Sigma |\beta_i|\biggl\} \qquad \qquad \text{which is LASSO with $\lambda = \frac{2\sigma^2}{b}$} \\ \end{align*}\)
In this view, Lasso and Ridge are Bayes estimates with different priors. They are derived as posterior modes, that is, maximizers of the posterior. It is more common to use the mean of the posterior as the Bayes estimate. Ridge regression is also the posterior mean, but the Lasso is not.
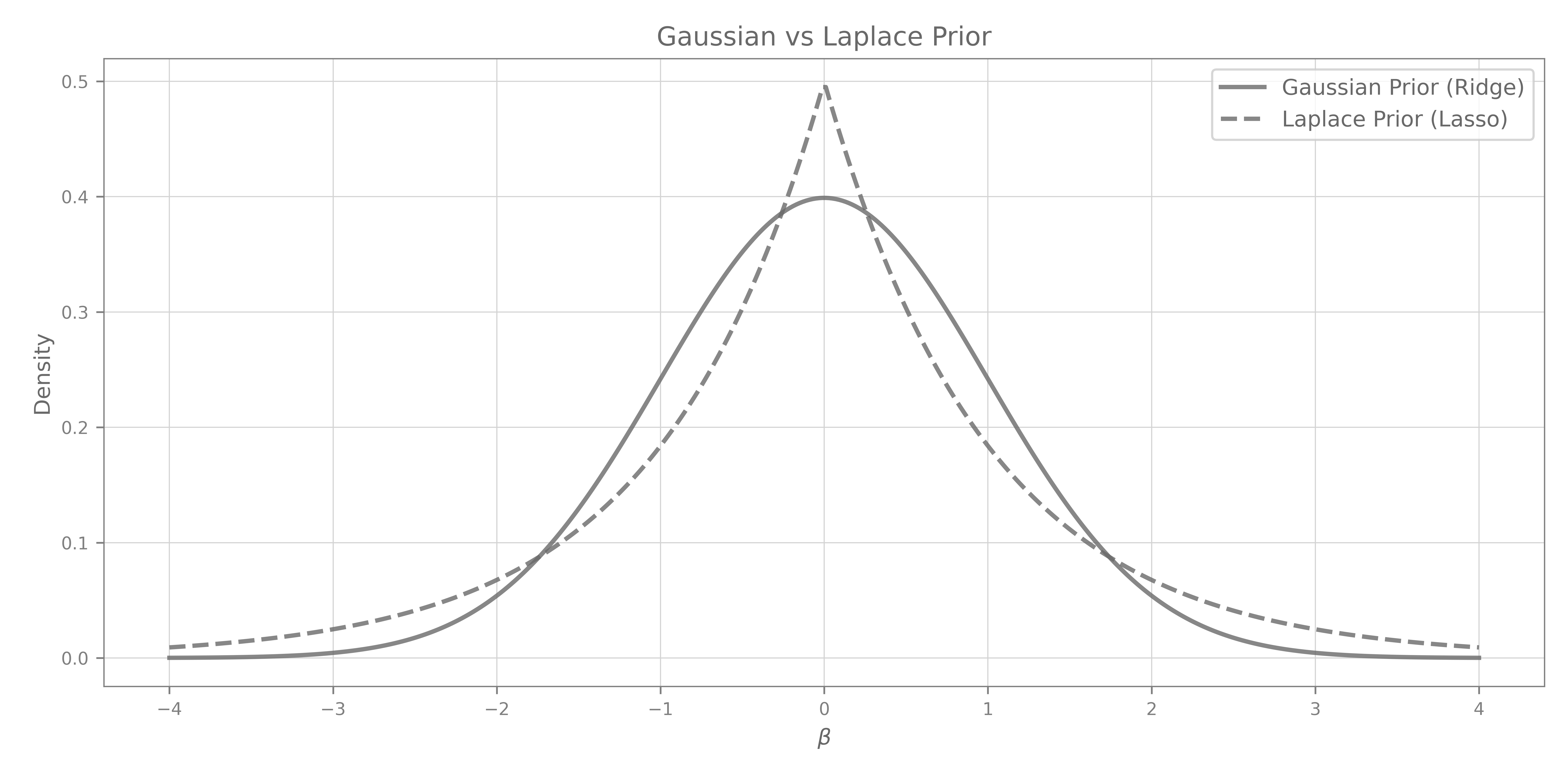
One can easily see how the definitions of regularization as priors on the distribution of the coefficients relate to their shrinking behavior. Imagine your OLS solution $\hat{\beta}$ as a point on one of the two prior curves (Gaussian for Ridge, Laplace for Lasso), and the shrinking process as the effect of these priors “pulling” the estimate toward 0. Because the Laplace prior has a sharp peak at $0$, increasing the regularization coefficient $\lambda$ can pull a coefficient exactly to $0$. In contrast, the Gaussian prior is smooth at $0$, so the corresponding Ridge penalty only shrinks coefficients continuously toward $0$ and never forces them to be exactly zero.
Elastic-Net
In Ridge, we minimize $RSS + \lambda |\beta|^2$, and in Lasso, $RSS + \lambda |\beta|$. Elastic-net introduces a compromise, that has both selects variables like Lasso, and shrinks together the coefficients of correlated predictors like Ridge:
\[\textit{minimize} \qquad RSS + \lambda \Sigma (\alpha \beta_j^2 + (1-\alpha)|\beta_j|)\]This introduces an extra parameter $\alpha$ that defines the strength of the L2-Norm relative to the L1-Norm.
You can compute the solution using the LARS-EN algorithm for the same computational cost as Lasso.
Lasso vs Ridge
Rotational Invariance
Ridge is Rotationally Invariant (e.g., the learning procedure and evaluation is unchanged when applying a rotation to the features on both the training and testing set. Intuitively, this mixes informative and uninformative signals. So to remove uninformative features, a rotationally invariant algorithm has to first find the original orientation of the features).
Rotational Invariance (Ng, 2004):
Let $\mathcal{M} = {M \in \mathbb{R}^{n \times n} : MM^T = M^TM = I, |M| = 1}$ be the class of rotation matrices.
A learning algorithm $\mathcal{L}$ is rotationally invariant if, for any training set $S$, rotation matrix $M \in \mathcal{M}$, and test example $x$: \(\mathcal{L}[S](x) = \mathcal{L}[MS](Mx)\) where $MS = {(Mx^{(i)}, y^{(i)})}_{i=1}^m$.
Intuition: The algorithm’s predictions don’t change when we rotate the coordinate system.
Rotational invariance has showned to be the cause for ineffective feature selection in ML algorithms. The reason is that you need a lot more samples for the algo to first learn the rotation then perform variable selection. I highly encourage to read the paper Feature selection, L1 vs. L2 regularization and rotational invariance by the great Andrew Ng.
Ridge constraint is $L2$ so it is a circle, symmetric in all directions (rotation invariant). Lasso constraint is $L1$ so it is a diamond with corners pointing along the coordinate axis, so not rotationally invariant.
In a Sparse Environment:
- If the important features are correlated, you’re effectively in a Sparser environment, as you can combine the non-noise features into more important ones so Lasso outperforms.
- If the noise is correlated, you can reduce the noise dimensionality so you end up in a less-sparse environment, where Lasso suffers. In general, Lasso suffers when the true signal is non-sparse because it tends to overshrink small but important coefficients, adding some bias. Lasso loses more performance than Ridge when you go froma sparse to a non-sparse environment. So you want the dimension reduction capability to be larger on important predictors than on noise.
- If you have general correlation (across both features and noise), ElasticNet will work best. It actually outperforms both Ridge and Lasso in most settings.
Rotational Invariance and Sparsity are tightly related. If you have a highly sparse data and you apply a rotation, you’re mixing the important features with a lot of noise. This is why Ridge which is rotation invariant is worse than Lasso in high-sparsity regimes.
The Grouping Effect
What is the grouping effect? It’s a property of ML algorithms to put similar weights to similar features. Simple no?
The Grouping Effect (definition by Zou and Hastie, in Regularization and variable selection via the elastic net (2005)):: A regression method exhibits the grouping effect if the coefficients of highly correlated variables tend to be equal (up to a change of sign).
But why should we care about that?
- In domains like economics, finance, or biology, related variables often move together and selecting them together makes the mode align with domain knowledge. For example, Genes in the same pathway should be selected togethe
- Correlated predictors jointly carry information about the response. Arbitrary exclusion may lose useful signal.
- Small perturbations in data shouldn’t drastically change which variable is selected. This is about stability in variable selection
- Interpretability: Identifies groups of important features, not arbitrary singletons. Lasso has indeed the tendency to “arbitrarily” choose one predictor amongst a group of highly correlated ones and set the rest to 0.
Assume $x_i = x_j$ (identical predictors). Consider the penalized regression:
\[\hat{\beta} = \arg\min_{\beta} \|y - X\beta\|^2 + \lambda J(\beta)\]Strictly convex $J(\cdot)$: \(\hat{\beta}_i = \hat{\beta}_j, \quad \forall \lambda > 0\)
Lasso ($J(\beta) = |\beta|_1$): \(\hat{\beta}_i \hat{\beta}_j \geq 0\). But $\hat{\beta}_i$ may $\neq \hat{\beta}_j$
Only strict convexity, (which Lasso doesn’t have) guaranties grouping.
Why Elastic-Net wins
I should probably start by dropping this Theorem, from Variable selection via nonconcave penalized likelihood and its oracle properties, from Jiangqing Fan and Runze Li (2001): In the $L_q$ penalty family (for \(q\geq 1\)), only the Lasso ($q = 1$) produces sparse solutions.
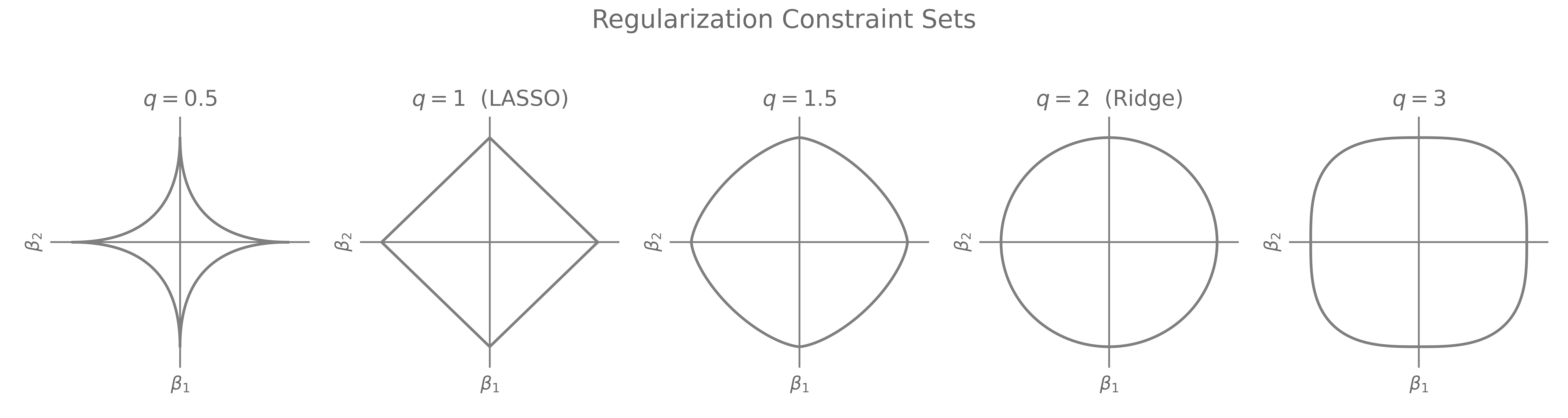
This basically means that Bridge Regression, which is regression with regularization \(q \in (1,2]\), i.e. between Ridge and Lasso, does not have sharp corners. So it cannot perform Variable Selection.
So what do we want really out of our linear model?
- Variable Selection
- Grouping Effect
- Non - Rotational Invariance
Turns out that Elastic-Net satisfies all 3 of those criterias. It can perform Variable Selection by having those sharp corners in its constraint region. It also has the grouping effect, as the constraint is strictly convex. Finally, it is also non-rotationally invariant. So Elastic-Net FTW.
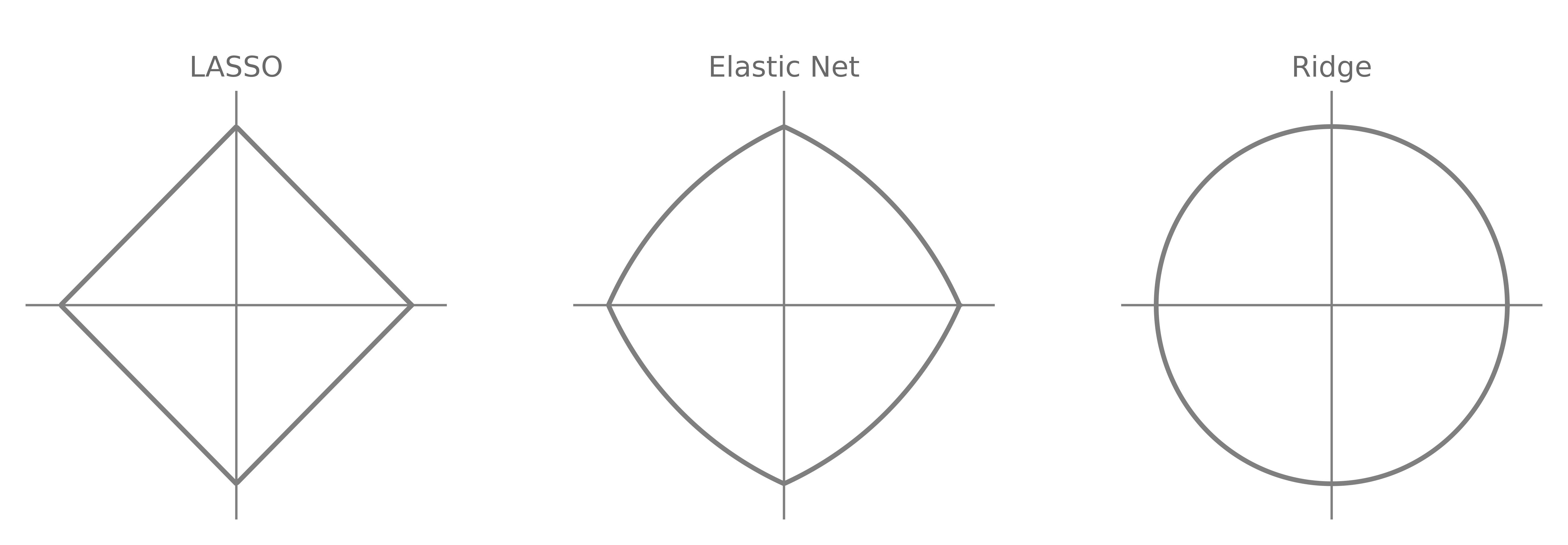
I still use Ridge, though.
References
The Elements ofStatistical Learning: Data Mining, Inference, and Prediction. (2009)
Trevor Hastie, Robert Tibshirani, Jerome Friedman
Book
Lecture notes on ridge regression (2023)
Wessel N. van Wieringen
Notes
Regularization and variable selection via the elastic net (2005)
Hui Zou, Trevor Hastie
Paper
Variable selection via nonconcave penalized likelihood and its oracle properties (2001)
Jianqing Fan, Runze Li
Paper
Feature selection, L1 vs. L2 regularization, and rotational invariance (2004)
Andrew Ng
Paper